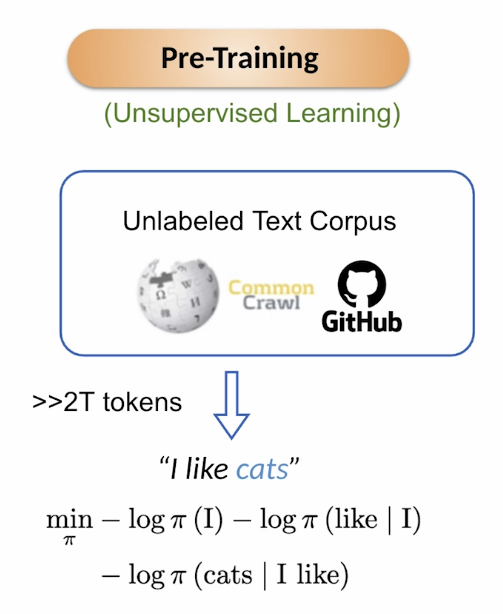
Post-training LLMs
Post training is essentially all about changing the model behavior after the extensive initial model pretraining.
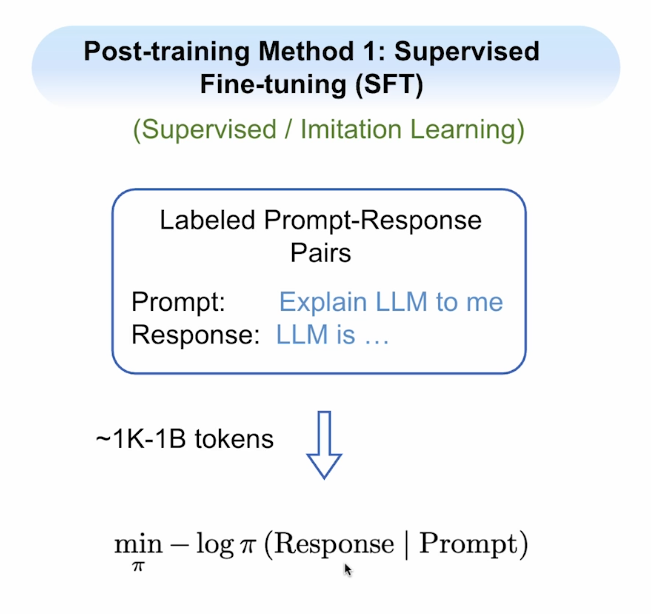
1. Supervised Fine-tuning (SFT)
SFT helps the model imitate example responses by learning from examples of prompts and desired outputs.
The loss function for supervised fine-tuning:
SFT minimizes negative log likelihood for the responses (maximizes likelihood) with cross entropy loss.
The result is an instruct model (finetuned model) that can answer users queries properly if done correctly.
SFT Use cases:
- Jumpstarting new model behavior:
- Pre-trained models -> instruct models
- Non-reasoning models -> reasoning models
- Let the model use certain tools without providing tool descriptions in the prompt.
- Improving model capabilities:
- Distilling capabilities for small models by training on high-quality synthetic data generated from larger models.
Common methods for high-quality SFT data curation:
- Distillation: Generate responses from a stronger and larger instruct model.
- Best of K / rejection sampling: Generate multiple responses from the original model, select the best among them.
- Filtering: start from larger scale SFT dataset, filter according to the quality of responses and diversity of the prompts.
Quality > quantity for improving capabilities:
- 1,000 high-quality, diversity data > 1,000,000 mixed-quality data.
2. Direct Preference Optimization (DPO)
- DPO utilizes Contrastive Learning from Positive and Negative Samples
- DPO minimizes the contrastive loss which penalizes negative response and encourages positive response.
- DPO loss is a cross entropy loss on the reward difference of a "re-parameterized" reward model.
The loss function for DPO:

Best Use Cases for DPO:
- Making small modifications of model responses
- Identity
- Multilingual
- Instruction following
- Safety
- Improving model capabilities
- Better than SFT in improving model capabilities due to contrastive nature
- Online DPO is better for improving capabilities than offline DPO
Common methods for high-quality DPO data curation:
- Correction: Generate responses from original model as negative, make enhancements as positive response
- Example: I'm Llama (Negative) -> I'm Athene (Positive)
- Online / On-policy: Your positive & negative example can both come from your model's distribution. One may generate multiple responses from the current model for the same prompt, and collect the best response as positive sample and the worst response as negative.
- One can choose best / worst response based on reward functions / human judgement.
Avoid overfitting:
- DPO is doing reward learning which can easily overfit to some shortcut when the preferred answers have shortcuts to learn compared with the non-preferred answers
- Example: when positive sample always contains a few special words while negative samples do not.
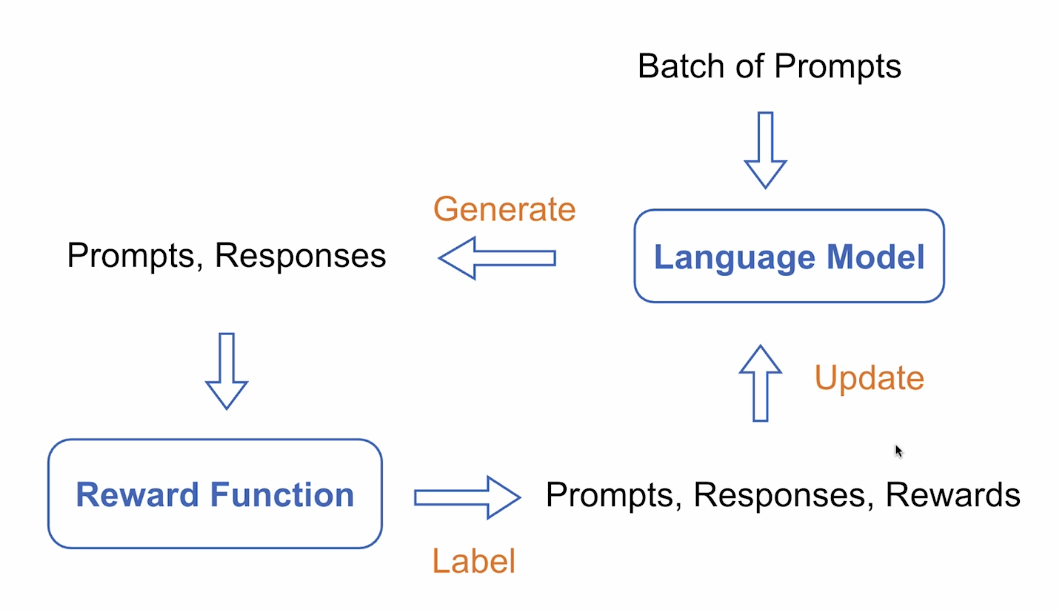
3. Online Reinforcement Learning

Online Learning:
- The model learns by generating new responses in real time -- it iteratively collects new responses and their reward, updates its weights, and explores new responses as it learns.
Offline Learning:
- The model learns purely from a pre-collected prompt - response (-reward) tuple. No fresh responses generated during the learning process.
Process:
Reward Function in Online RL:
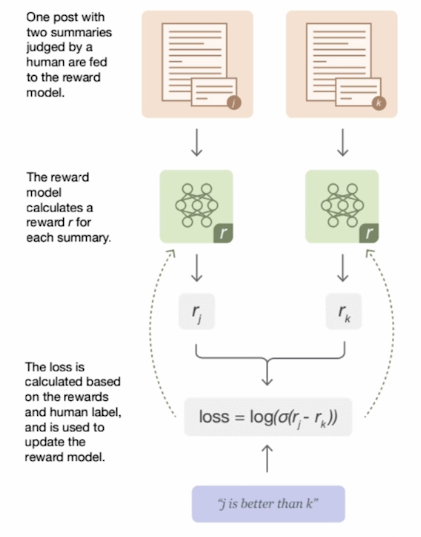
1. Trained Reward Model
- Usually initialized from an existing instruct model, then train on large-scale human / machine generated preference data
- Works for any open-ended generations
- Good for improving chat & safety
- Less accurate for correctness-based domains like coding, math, function calling, etc
2. Verifiable Reward
- Requires preparation of ground truth for math, unit tests for coding, or sandbox execution environment for multi-turn agentic behavior.
- More reliable than reward model in those domains
- Used more often for training reasoning models
Policy Training in Online RL
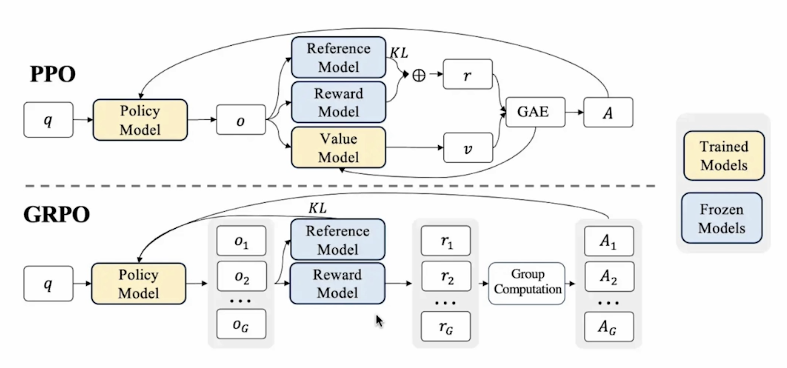
- Both GRPO and PPO are very effective online RL algorithms!
- GRPO:
- Well-suited for binary (often correctness-based) reward
- Requires larger amount of samples
- Requires less GPU memory (no value model needed)
- PPO:
- Works well with reward model or binary reward
- More sample efficient with a well-trained value model
- Requires more GPU memory (value model)
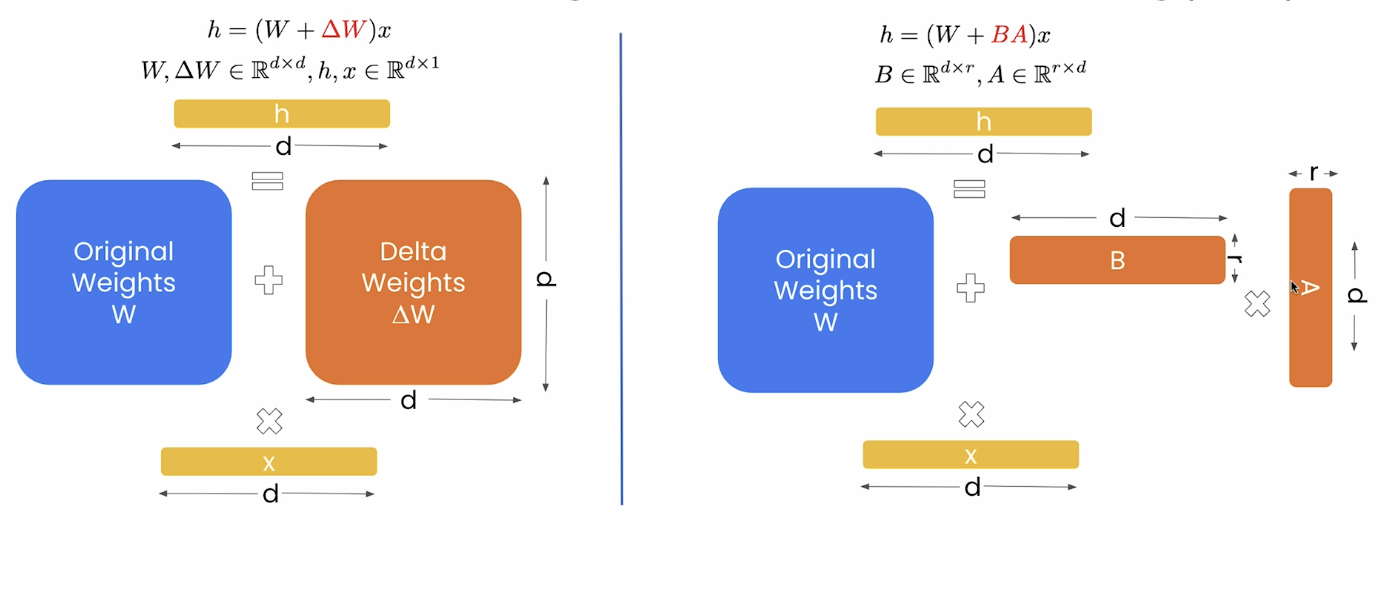
Full Fine-tuning vs Parameter Efficient Fine-tuning (PEFT)