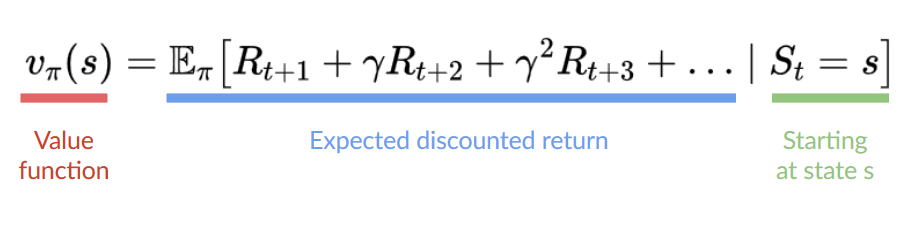Learn in Public | Introduction to Deep Reinforcement Learning Course by Huggingface
Overview
These are my notes following the Deep Reinforcement Learning Course by Huggingface
Syllabus
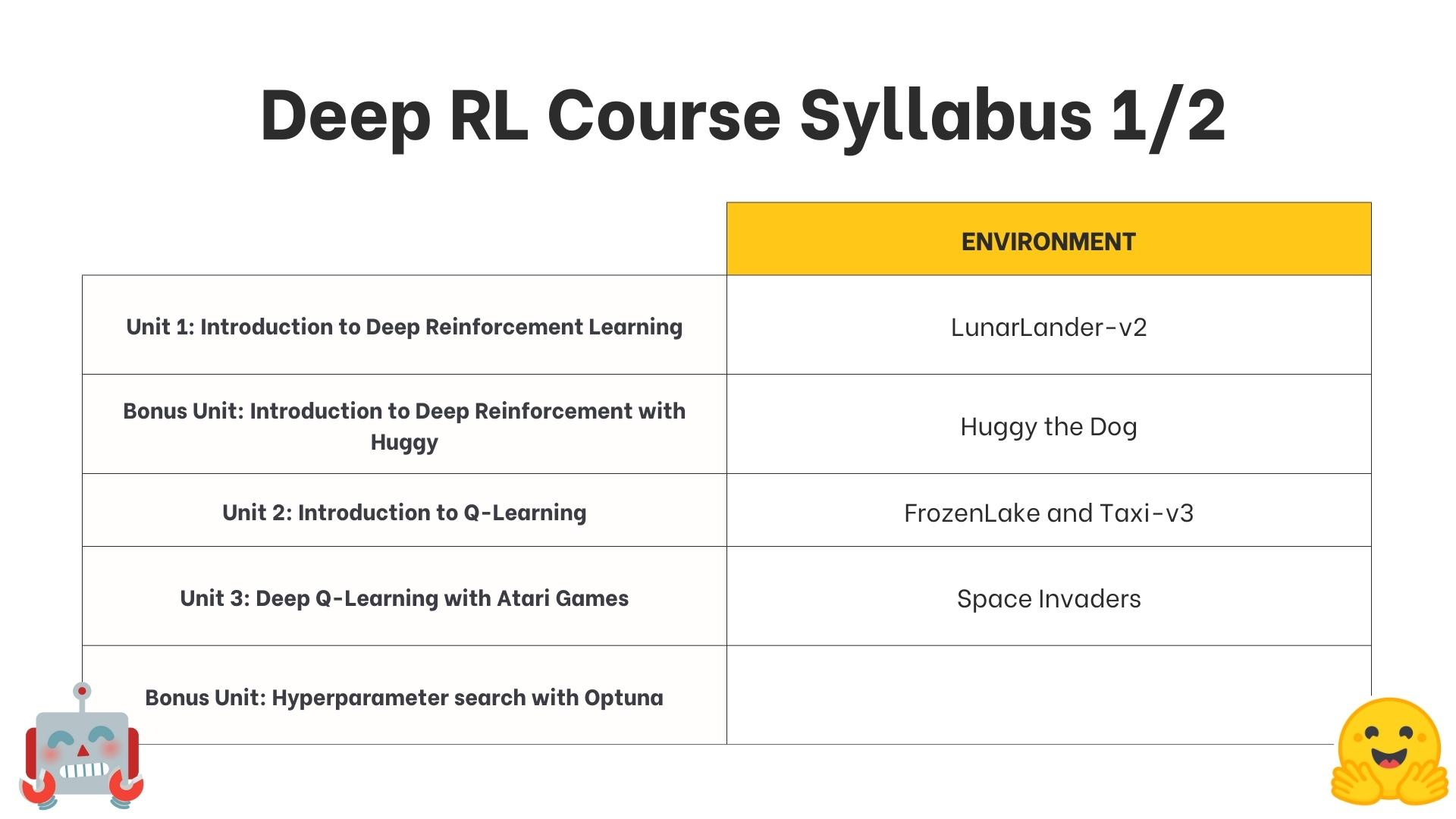
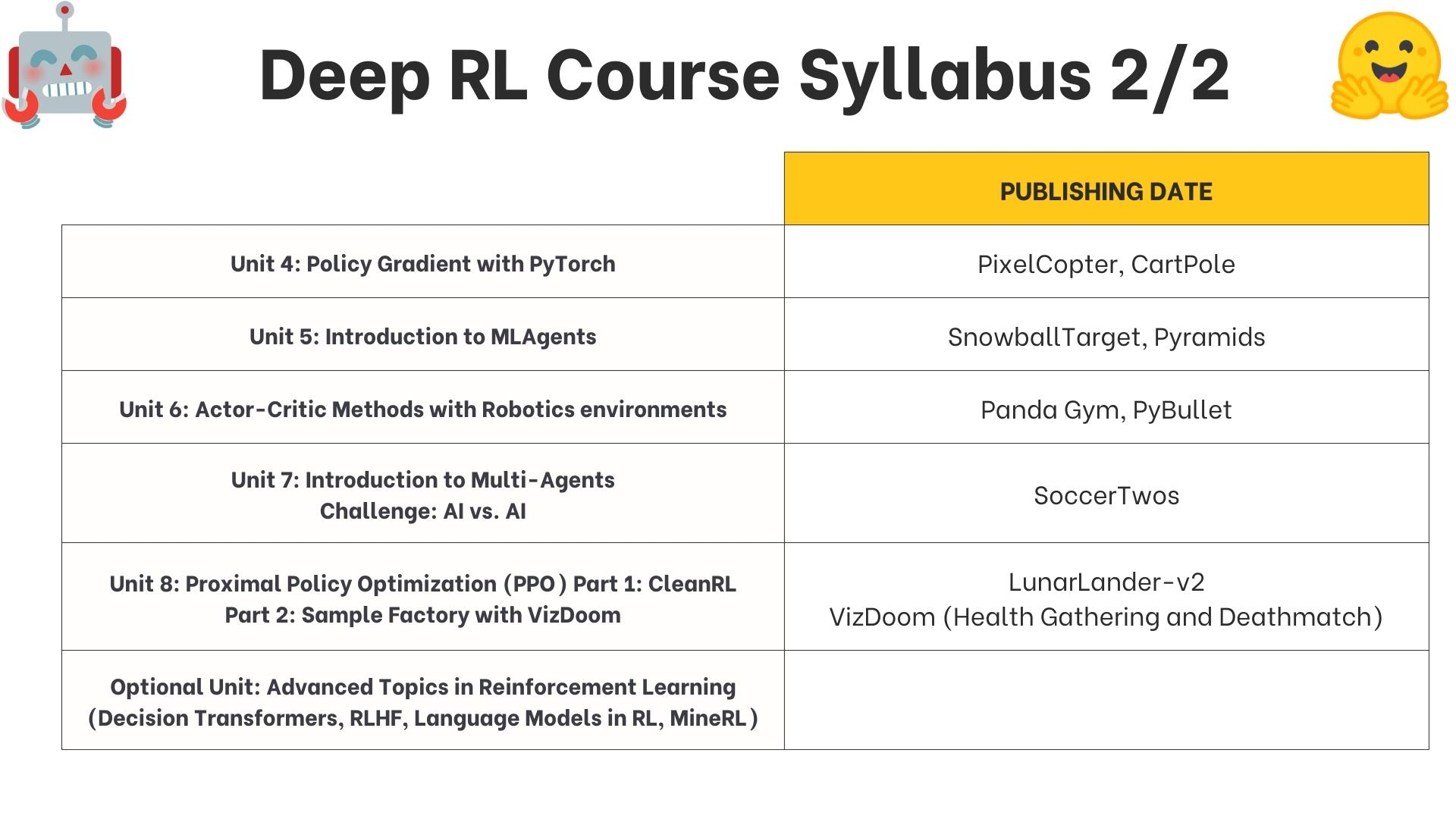
Unit 1: Introduction to Deep Reinforcement Learning:
Goal:
train a Deep Reinforcement Learning agent, a lunar lander to land correctly on the Moon using Stable-Baselines3 , a Deep Reinforcement Learning library.
The big picture:
The idea behind Reinforcement Learning is that an agent (an AI) will learn from the environment by interacting with it (through trial and error) and receiving rewards (negative or positive) as feedback for performing actions.
A formal definition:
Reinforcement learning is a framework for solving control tasks (also called decision problems) by building agents that learn from the environment by interacting with it through trial and error and receiving rewards (positive or negative) as unique feedback.
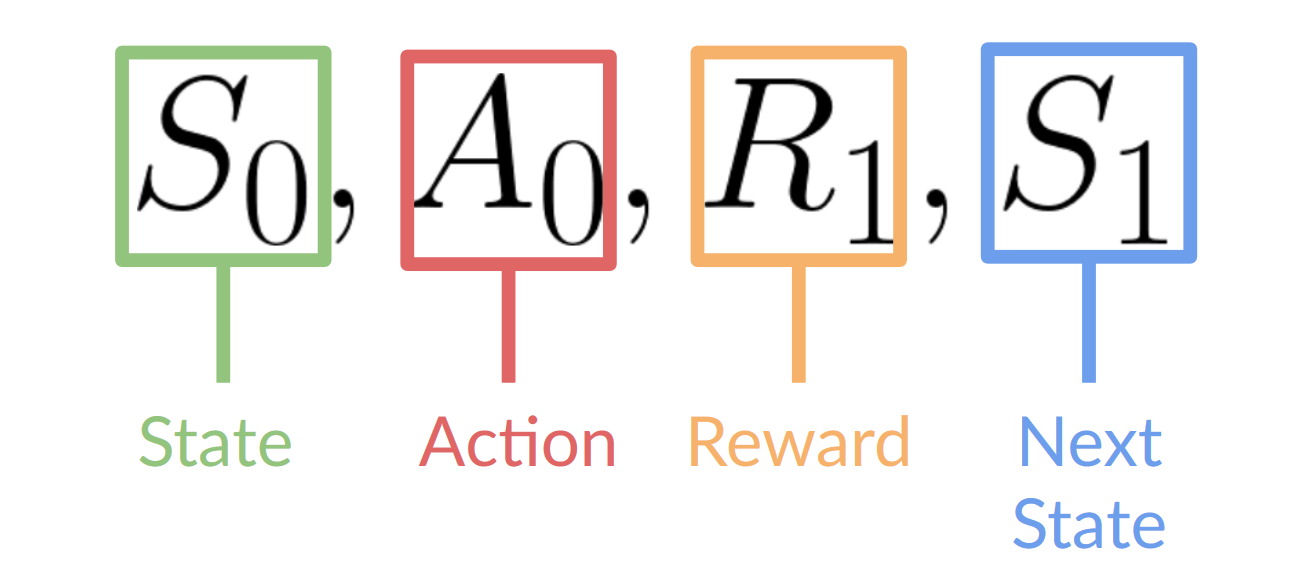
The reinforcement learning framework:
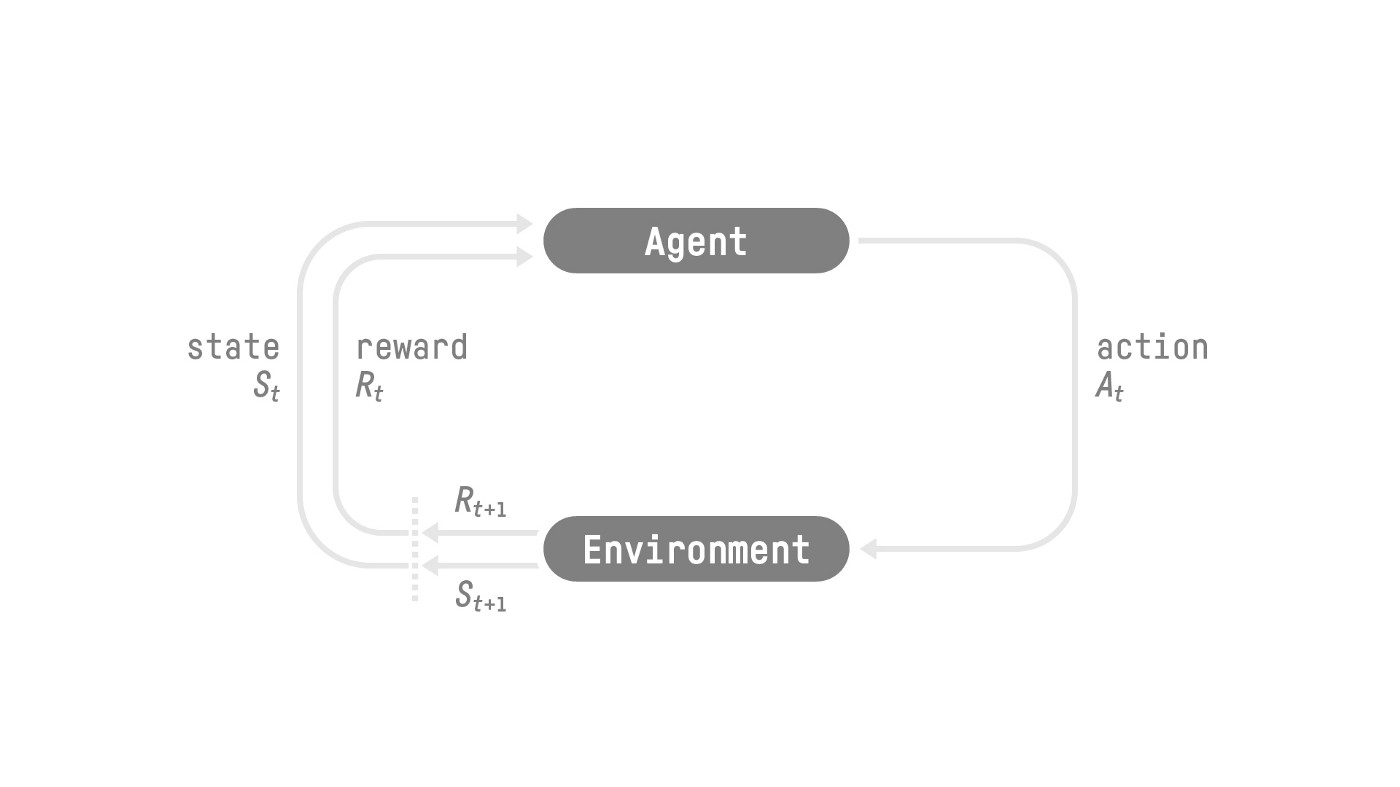
- Our Agent receives state S_0 from the Environment — we receive the first frame of our game (Environment).
- Based on that state S_0, the Agent takes action A_0 — our Agent will move to the right.
- The environment goes to a new state S_1 — new frame.
- The environment gives some reward R_1 to the Agent — we’re not dead (Positive Reward +1).
This RL loop outputs a sequence of state, action, reward and next state.
The agent’s goal is to maximize its cumulative reward, called the expected return.
The reward hypothesis: the central idea of Reinforcement Learning
- Why is the goal of the agent to maximize the expected return?
Because RL is based on the reward hypothesis, which is that all goals can be described as the maximization of the expected return (expected cumulative reward).
That’s why in Reinforcement Learning, to have the best behavior, we aim to learn to take actions that maximize the expected cumulative reward.
Markov Property
- In papers, the RL process is often called a Markov Decision Process (MDP).
- The Markov Property implies that our agent needs only the current state to decide what action to take and not the history of all the states and actions they took before.
Observations/States Space
-
Observations/States are the information our agent gets from the environment. In the case of a video game, it can be a frame (a screenshot). In the case of the trading agent, it can be the value of a certain stock, etc.
-
to recap:

Action Space
The Action space is the set of all possible actions in an environment.
The actions can come from a discrete or continuous space:
-
Discrete space: the number of possible actions is finite.
-
Continuous space: the number of possible actions is infinite.
-
to recap:

Rewards and the discounting:
-
The reward is fundamental in RL because it’s the only feedback for the agent. Thanks to it, our agent knows if the action taken was good or not.
-
The cumulative reward at each time step t can be written as:
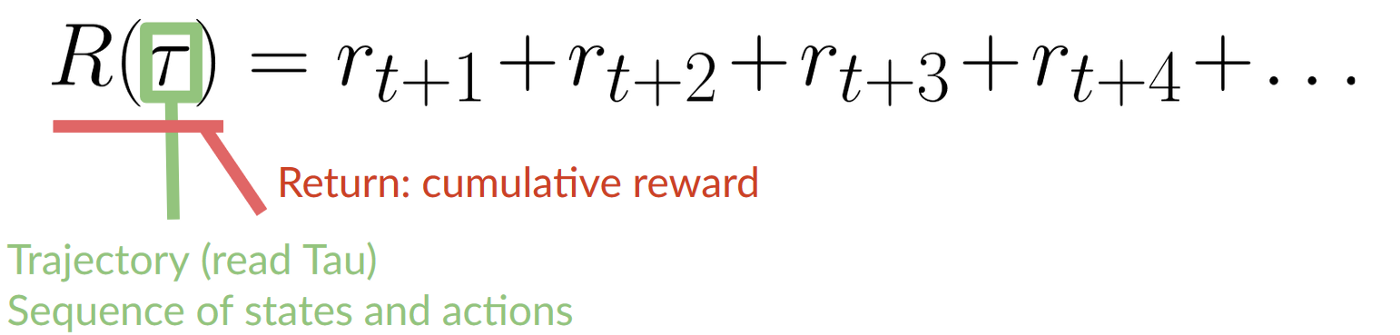
-
Which is equivalent to:
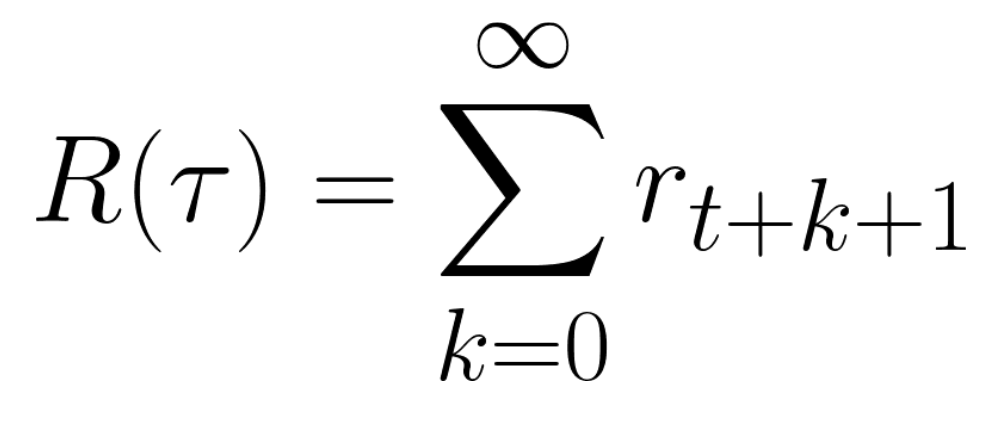
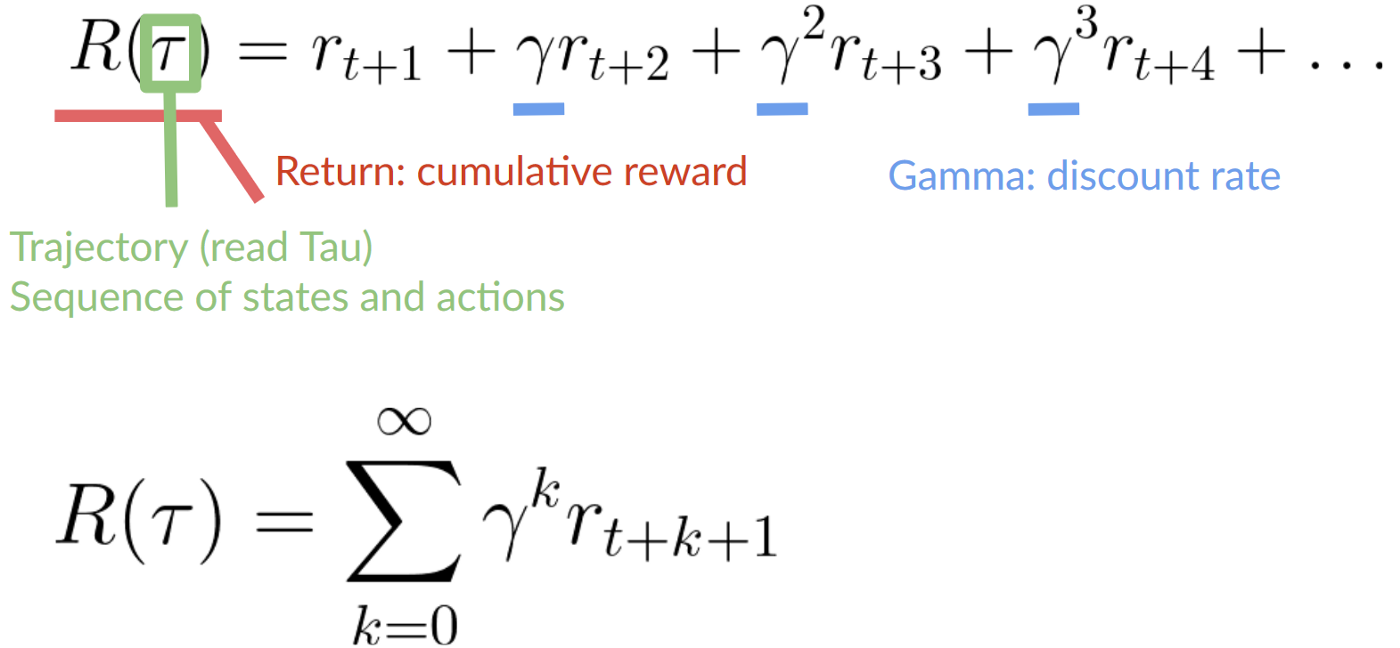
Our discounted expected cumulative reward is:
The type of tasks
-
Episodic task
In this case, we have a starting point and an ending point (a terminal state). This creates an episode: a list of States, Actions, Rewards, and new States. -
Continuing tasks
These are tasks that continue forever (no terminal state). In this case, the agent must learn how to choose the best actions and simultaneously interact with the environment.
The exploration/exploitation trade-off
- Exploration is exploring the environment by trying random actions in order to find more information about the environment.
- Exploitation is exploiting known information to maximize the reward.
The two main approaches for solving RL problems
-
The Policy π: the agent’s brain:
The Policy π is the brain of our Agent, it’s the function that tells us what action to take given the state we are in. So it defines the agent’s behavior at a given time. -
demonstration of the policy function:
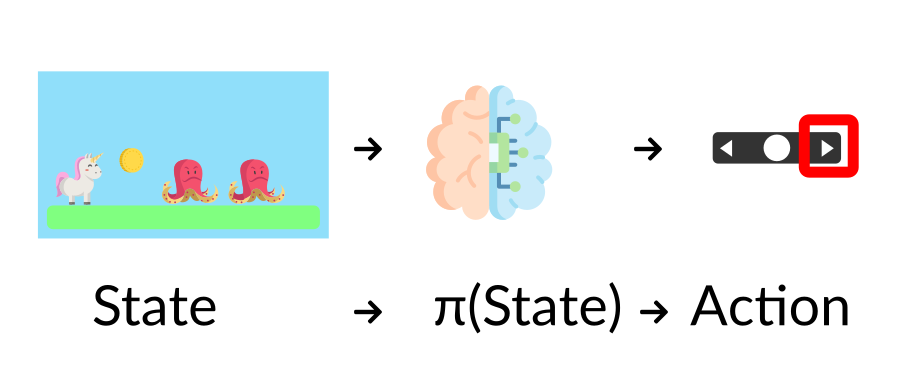
-
This Policy is the function we want to learn, our goal is to find the optimal policy π*, the policy that maximizes expected return when the agent acts according to it. We find this π* through training.
-
There are two approaches to train our agent to find this optimal policy π*:
- Directly, by teaching the agent to learn which action to take, given the current state: Policy-Based Methods.
- ndirectly, teach the agent to learn which state is more valuable and then take the action that leads to the more valuable states: Value-Based Methods.
-
Policy-Based Methods:
In Policy-Based methods, we learn a policy function directly.
This function will define a mapping from each state to the best corresponding action. Alternatively, it could define a probability distribution over the set of possible actions at that state.We have two types of policies:
- Deterministic: a policy at a given state will always return the same action.
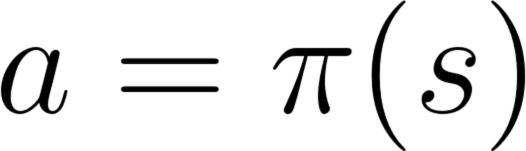
- Stochastic: outputs a probability distribution over actions.

- Deterministic: a policy at a given state will always return the same action.
-
Value-based methods
In value-based methods, instead of learning a policy function, we learn a value function that maps a state to the expected value of being at that state.The value of a state is the expected discounted return the agent can get if it starts in that state, and then acts according to our policy.